Querying Marine Traffic API with web-scraped container ships data

Mikael Dautrey
Written on May 14, 2021
This article was initially posted on ISITIX blog, titled “Querying Marine Traffic API with web-scraped container ships data ”.
Marine Traffic operates a database of Maritime data. The database is fed with AIS data. Every AIS-equipped ship periodically radio-broadcasts information abouts its position, its speed, and so on. Marine Traffic operates ground stations to collect AIS-information and put them in a big central database, and offers a paid API to query it.
Our initial goal
We got Marine-Traffic API credits, which were to expire, from a previous client assignment. Rather than wasting them, we build a small POC around container ships data.
The goal we set for ourselves was to get a quick preview of container ships traffic around the globe. It’s a textbook case to show what can be done in a limited time with simple tools.
The use case is specific to the maritime business but the methodology can be applied to other use cases, from gathering contacts information to assessing the information available about an economic sector. This approach is useful every time a client asks a question about business intelligence or another form of external intelligence. The same process is interesting when enriching internal data with external sources too.
Global container ships fleet
More than two thousands container ships operate around the world. The following steps have to be taken to get an overview of the corresponding maritime traffic:
- Establishing a fleet of ships you want to track
- Querying the AIS API to get information about ships in the fleet
- Restituing meaningful results from steps 1 and 2
In this tutorial, we goes through these three steps:
- For step 1, as our Marine Traffic subscription doesn’t give us access to their advanced fleet query tools, we scrape the web to draw-up a list of container ships to track.
- For step 2, we query the Marine Traffic API. To limit credits consumption, we cache results.
- Step 3 depends on our client request. As it’s a POC, we only provide some simple aggregate results and let you enrich it with your current use case.
Tools of the trade
The code is written in Python.
This tutorial requires five libraries :
- BeautifulSoup is a powerful HTML and XML parser that we call to parse both HTML pages (web scrapping) and the XML response from Marine Traffic Rest API
- requests is a standard library (a bit low level) to query Rest API
- numpy array offers a flexible data structure that is easy to query, filter and persist on disk
- matplotlib offers the minimal drawing functionalities we need.
- pandas functionnalities greatly simplify data analysis
from bs4 import BeautifulSoup
import requests
import random
import numpy as np
from matplotlib import pyplot as plt
import pandas as pdData persistency
In this example, persistency relies on numpy save function. This solution is better than nothing. It does the job we need (but not more :-)).
We manage a status that has three possible values:
- NO = no data available,
- STORED = data comes from a former query and was saved on disk,
- FRESH = data comes from the last API call.
SHIPS_DATA_CACHE_FILENAME = './cache/ships.npy'
POSITIONS_DATA_CACHE_FILENAME = './cache/positions.npy'
def load_data(cache_filename, status = "NO"):
if status == "NO":
try:
data = np.load(cache_filename, allow_pickle=True)
status = "STORED"
return (data, status)
except IOError:
return (None, "NO")
(ships_data, ships_loaded) = load_data(SHIPS_DATA_CACHE_FILENAME)
(positions_data, positions_loaded) = load_data(POSITIONS_DATA_CACHE_FILENAME)Getting vessels information from a Web page
There are many web sites where you will find lists of vessels classified by category, company, flag or other criteria. Some are open, others are closed, some are free, others not. You must check that the use you consider is compatible with the legal mentions of the site you query. When in doubt, you may contact its webmaster.
On a dynamic site, URL are generally structured. In this example, the URL was BASE_URL/company_name?page=page_number .
We load every page of a company. On each page, we retrieve information about vessels by parsing HTML code with BeautifulSoup. We didn’t make our code generic. It would add much complexity and wouldn’t really make sense as we only deal with a single web site and a few HTML pages.
The function takes the number of pages as an argument. We get the number of pages by manually browsing the site. This way of doing is not very scalable but sufficient in our case. As the number of pages is often displayed at the bottom of the page, we could get it by parsing the code.
Numpy array are, in our understanding, rather immutable beasts. We put vessel position rows in a plain python array and we then batch-load them in a numpy-array.
def get_fleet(company_name, pages = 0):
"""
list of vessels for company_name, browsed from page 1 to page pages
"""
BASE_URL = 'YOUR FAVORITE VESSEL TRACKING WEBSITE'
url = BASE_URL + company_name
fleet = []
for page in range (1, pages + 1):
if page == 1:
response = requests.get(url)
else:
response = requests.get(url, params = {'page': page})
soup = BeautifulSoup(response.text, 'html.parser')
for tr in soup.find_all('tr'):
if tr.has_attr('data-key'):
tds = tr.find_all('td')
imo = int(tr['data-key'])
flag = tds[1].find('i')['title'].strip()
ship_name = tds[1].text.strip()
built_year = int(tds[3].text)
TEU = float(tds[4].text)
length = float(tds[5].text)
ship_record = (imo, flag, ship_name,
built_year, TEU, length, company_name)
fleet.append(ship_record)
return fleetParsing many web pages
Our routine to parse a web page is now functionnal. We could build a repository of pages we want to parse. To keep things as simple as possible, we use a dictionnay of the five biggest companies for which we get their vessels inventory.
As mentionned earlier:
- the number of pages for each company is hard-coded, but making it dynamic will be easy
- results are batch-loaded into a numpy array at the end of the parsing process
- we parse (and query) the web pages only once. Then we get data from our local cache.
if ships_loaded == "NO":
pages = {'msc': 5, 'maersk': 5, 'cosco': 13, 'hapag-lloyd': 1, 'cma-cgm': 2}
fleets = []
for company in pages :
company_fleet = get_fleet(company, company_pages[company])
fleets.extend(company_fleet)
ships_data = np.array(fleets, dtype=[('imo','i4'),('flag','U32'),('ship_name','U64'),('build_year','i2'),\
('TEU','f4'),('length','f4'),('company_name','U16')])
ships_loaded = "FRESH"Saving results locally to avoid duplicating queries
To prevent us from querying external web sites every time we load vessels information, we save it on our local disk, a simple process that could in the future be improved by loading information into a database rather than a flat file.
if ships_loaded == "FRESH":
np.save(SHIPS_DATA_CACHE_FILENAME, ships_data, allow_pickle=True)Querying Marine Traffic API
Marine Traffic publishes API to track ships and ports activity. It is a paid service, with a pay-per-use pricing. So, you have to think about what you really need to limit the bill and to store results to limit query volume.
Storing results of queries to get vessels characteristics, for instance, saves cost because they don’t change much with time.
In this example, we query the single vessel positions service to get the position of the vessels in our fleet. Every service requires an API key you get from Marine Traffic. A few parameters must be set. You’ll find the various options in the documentation.
def get_vessel_position(ship_imo):
MT_PS07_API_KEY = 'YOUR_API_KEY'
MT_PS07_URL = 'https://services.marinetraffic.com/api/exportvessel/v:5/'
params = {'protocol' : 'xml', 'timespan': '30000', 'imo':ship_imo}
url_params = '/'.join(map(lambda x: x + ':' + str(params[x]), params))
url = MT_PS07_URL + '/' + MT_PS07_API_KEY + '/' + url_params
return requests.get(url)
def parse_vessel_position(response):
if '<row' in response.text:
soup = BeautifulSoup(response.text)
position_data = soup.find('row').attrs
# (imo, mmsi, lat, lon, speed, heading, course, status, timestamp, dsrc )
result = (int(position_data['mmsi']), float(position_data['lat']), float(position_data['lon']), \
float(position_data['speed'])/100.0, int(position_data['heading']), int(position_data['course']), \
int(position_data['status']), np.datetime64(position_data['timestamp']), position_data['dsrc'])
return result
return None
if positions_loaded == "NO":
positions = []
for ship_imo in ships_data['imo']:
response = get_vessel_position(ship_imo)
vessel_data = parse_vessel_position(response)
if vessel_data != None:
positions.append((vessel_data))
positions_data = np.array(positions, dtype=[('imo','i4'),('mmsi','i4'),('lat','f4'),\
('lon','f4'),('speed','f4'),('heading','i4'),\
('course','i4'), ('status','i4'),\
('timestamp','datetime64[s]'), ('dsrc', 'U8')])Saving results locally for future uses
We save results locally for future uses.
if positions_loaded == "FRESH":
np.save(POSITIONS_DATA_CACHE_FILENAME, positions_data, allow_pickle=True)Information we gathered in the process
We build two arrays, ships_data and positions_data.
ships_data contains the following fields for five major container ship companies:
- imo
- flag
- ship name
- build year
- TEU: twenty foot equivalent unit
- length (meters)
- company name
positions_data contains the following fields:
- imo : vessel identification
- mmsi : vessels unique id
- latitude
- longitude
- speed
- heading
- course
- status: under way, at anchor… read the documentation here to know more about status
- timestamp : time when the position was measured
- dsrc : datasource, either terrestrial (AIS) or satellite
Sample data
We can view a sample of these arrays at random to discover data :
positions_data.take(random.randint(0, len(positions_data)))(9223758, 412277000, 24.35305, 120.4848, 15.4, 14, 15, 0, '2020-05-13T16:07:36', u'TER')ships_data.take(random.randint(0, len(ships_data)))(8511990, u'Panama', u'XINYUAN HAI', 1988, 0., 290.03, u'cosco')Filtering data
We filter data to drop every row where the length is less than 10 meters or the capacity is less than 10 TEU.
Length, TEU, build year
Length versus TEU
ship_spec = ships_data[(ships_data['TEU']> 10.) & (ships_data['length']> 10)]
plt.scatter(ship_spec['length'], ship_spec['TEU'])
plt.xlabel('length')
plt.ylabel('TEU')
plt.show()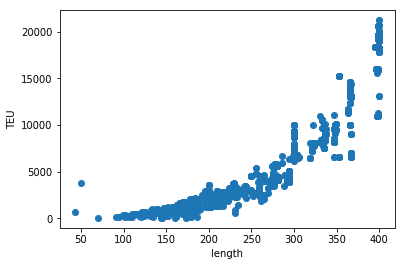
Length versus build year
plt.scatter(ship_spec['build_year'], ship_spec['length'])
plt.xlabel('build year')
plt.ylabel('length')
plt.show()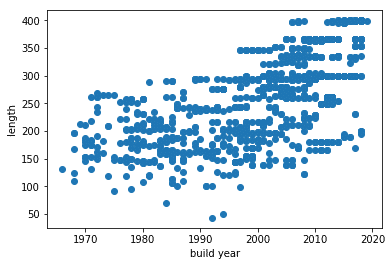
CMA-CGM fleet
cma_ship_spec = ship_spec[ship_spec['company_name']== 'cma-cgm']plt.scatter(cma_ship_spec['length'], cma_ship_spec['TEU'])
plt.xlabel('length')
plt.ylabel('TEU')
plt.show()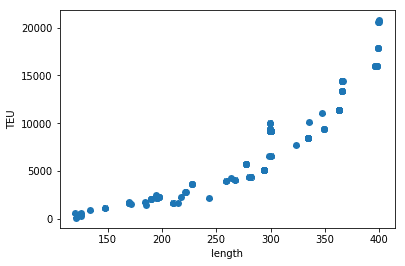
plt.scatter(cma_ship_spec['build_year'], cma_ship_spec['length'])
plt.xlabel('build year')
plt.ylabel('length')
plt.show()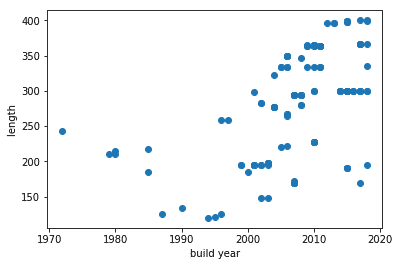
CMA-CGM ships below 150 meters length
cma_ship_spec[cma_ship_spec['length'] < 150]array([(9265586, u'Portugal', u'CMA CGM AGADIR', 2003, 1118., 148. , u'cma-cgm'),
(9265574, u'Indonesia', u'CMA CGM JAKARTA', 2002, 1118., 148. , u'cma-cgm'),
(9132399, u'Panama', u'DIANA K', 1996, 642., 125.3 , u'cma-cgm'),
(9050814, u'France', u'MARION DUFRESNE', 1995, 109., 120.75, u'cma-cgm'),
(9064700, u'Malta', u'FAS VAR', 1994, 599., 119.99, u'cma-cgm'),
(8901638, u'Malta', u'RABAT', 1990, 976., 133.7 , u'cma-cgm'),
(8420426, u'Panama', u'CAP CAMARAT', 1987, 347., 125.6 , u'cma-cgm')],
dtype=[('imo', '<i4'), ('flag', '<U32'), ('ship_name', '<U64'), ('build_year', '<i2'), ('TEU', '<f4'), ('length', '<f4'), ('company_name', '<U16')])Exploring Marine Traffic vessels position API
We only had around 500 credits left on Marine Traffic. After test, try-and-fail, we get the position of 408 vessels in our initial list of 2359 vessels.
"Positions found for {} found from a initial list of {} vessels".format(len(positions_data), len(ships_data))"Positions found for {} found from a initial list of {} vessels".format(len(positions_data), len(ships_data))Pandas
To analyse data further, we use pandas. Pandas is a library which plugs into numpy. It provides many tools to simplify data analysis.
positions = pd.DataFrame(positions_data, index=positions_data['imo'])
ships = pd.DataFrame(ships_data, index = ships_data['imo'])
full_ships_data = pd.concat([ships, positions], sort=True, axis=1)Companies fleet characteristics
ships.groupby('company_name').agg({'imo': np.count_nonzero, 'build_year':np.median, 'TEU':np.median,'length':np.median})| length | build_year | imo | TEU | |
| company_name | ||||
| cma-cgm | 299.820007 | 2010 | 153 | 6627.0 |
| cosco | 189.990005 | 2001 | 1215 | 0.0 |
| hapag-lloyd | 294.049988 | 2006 | 93 | 4843.0 |
| maersk | 257.500000 | 2008 | 452 | 4082.0 |
| msc | 252.199997 | 1999 | 446 | 2981.5 |
Company fleet status
Marine Traffic lets you know the status of the fleet of a given company.
We didn’t have sufficient credits left to get our full fleet status, but we give you a sample.
The status field is defined in Marine Traffic documentation:
- 0 = under way
- 1 = at anchor
- 5 = moored
- 8 under way sailing (???)
full_ships_data[['company_name', 'status','speed']].dropna().groupby(['company_name', 'status']).agg([np.count_nonzero, np.median])| speed | |||
| count_nonzero | median | ||
| company_name | status | ||
| cosco | 0.0 | 213.0 | 12.9 |
| 1.0 | 43.0 | 0.1 | |
| 5.0 | 23.0 | 0.0 | |
| 8.0 | 1.0 | 0.5 | |
lat_lon = full_ships_data[['imo', 'lat','lon']].dropna()Fleet position
plt.scatter(lat_lon.lon, lat_lon.lat)
plt.xlabel('longitude')
plt.ylabel('latitude')Text(0,0.5,'latitude')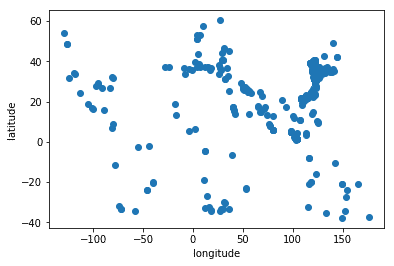
As a conclusion
With simple tools and some programming work, the web is a mine of information. The example we show here is around Marine Traffic API but you can imagine the same kind of investigation for DNS records, CVE, or marketing data.